Never do these mistakes when comparing regression models
Some time ago I stumbled upon some work by Patrick Walters which shows that correlation coefficients have a rather large standard error when the sample sets sizes are low. He even made a toolkit to make better comparisons: https://github.com/PatWalters/metk, and also uses this in an example comparing some aqueous solubility models: http://practicalcheminformatics.blogspot.com/2018/09/predicting-aqueous-solubility-its.html
This uncertainty in estimation of the correlation coefficients leads to difficulties when comparing the performance of different regressions models. If the test or development set size is low the differences are not statistically significant. This can be either in your own benchmarking of models or when comparing with reported models in literature. I was surprised actually a bit surprised by the large confidence intervals that had to be assigned and decided to experiment with some simulated data to get a better understanding of the issues and potential pitfalls. Read on below if you want to understand how to better compare regressions models.
Simulated data for modelling
In order to get some data to work on, We’ll make a simulated data set. This way it’s possible to make a large amount of data and at the same time know the exact processes that underlies them and thus compare the two machine learning
models we are going to build later with the perfect one. Here, the random module of numerical python is used to make three independent variables X1 to X3, which are responsible for the dependent variable y. All variables are then subjected to random permutations to simulate a noisy estimation or factors not related to our independant variables.
import numpy as np import matplotlib.pyplot as plt %matplotlib inline
samples=100000 #How many samples do we want? s = 2 #The standard deviation for the noise #Independent variables x1 = np.random.randn(samples)*10-5 x2 = np.random.randn(samples)*10-5 x3 = np.random.randn(samples)*10-5 #Dependant variable with some non-linear and linear contributions y1 = 1*np.sin(x1/10) + 1*x2 -0.5*x3 #Adding Noise x1_o = x1 + s*np.random.randn(samples) x2_o = x2 + s*np.random.randn(samples) x3_o = x3 + s*np.random.randn(samples) y = y1 + s*np.random.randn(samples) #Concatenate into a 2D array x = np.concatenate([x1_o.reshape((-1,1)),x2_o.reshape((-1,1)),x3_o.reshape((-1,1))], axis=1) x.shape
(100000, 3)
# Plotting the variable x2_o which has been assigned a linear relationship with y _ = plt.scatter(x2_o, y1, alpha=0.2)

Building a simple machine learning model
The first model is ridge regression. It’s a multiple linear regression with l2 regularization of the weights. The convenient scikit-learn implementation RidgeCV uses internal cross validation of the training set to fit the regularization parameter before a refit on the entire dataset.
from sklearn.linear_model import RidgeCV
A test set external to to the tuning of the hyperparameter is split off the full dataset.
from sklearn.model_selection import train_test_split x_tr, x_tst, y_tr, y_tst = train_test_split(x,y)
rgr = RidgeCV(cv=5)
rgr.fit(x_tr,y_tr)
y_pred = rgr.predict(x_tst)
plt.scatter(y_pred, y_tst, alpha=0.2)
print("%0.4F"%np.corrcoef(y_tst,y_pred)[0,1]**2)
0.9318

The model is able to find the underlying linear dependence between X and y, although not perfect due to the simulated noise. But there was also added a non-linear component, so maybe a non-linear model such as a random forest regressor can do better.
from sklearn.ensemble import RandomForestRegressor
rf = RandomForestRegressor()
rf.fit(x_tr,y_tr)
rf_y_pred = rf.predict(x_tst)
plt.scatter(rf_y_pred, y_tst, alpha=0.2)
print("%0.4F"%np.corrcoef(y_tst,rf_y_pred)[0,1]**2)
/home/esben/git/envs/ML_default/lib/python3.6/site-packages/sklearn/ensemble/forest.py:246: FutureWarning: The default value of n_estimators will change from 10 in version 0.20 to 100 in 0.22.
"10 in version 0.20 to 100 in 0.22.", FutureWarning)
0.9175

The random forest model doesn’t appear to have as good a fit as the Ridge model. But for this simple test, the hyperparameters of the model has not been tuned. Let us compare with the “perfect” model, which is the exact equation that was used to derive y, before the noise was added to X variables.
# The perfect model
y_pred_perf = 1*np.sin(x_tst[:,0]/10) + 1*x_tst[:,1] -0.5*x_tst[:,2]
plt.scatter(y_pred_perf, y_tst, alpha = 0.2)
print("R^2 %0.4F"%np.corrcoef(y_tst,y_pred_perf)[0,1]**2)
R^2 0.9325

So the ridge regression seems to be very close to the perfect model, probably because it is mostly linear processes we used from x2 and x3 and a low weight on the x1. The random forest regressor falls a bit behind, but only a little, and could probably be tuned a bit with respect to the hyperparameters. However, with these two models we can then return to the confidence intervals from the estimation of the correlation coefficient.
Calculation of confidence intervals for R^2
To calculate the confidence intervals around the correlation coefficient, r, it first need to be transformed to the z’ distribution via a Fishers transformation (arctanh). Otherwise it’s not normal distributed. You can read more on this Wikepedia page: https://en.wikipedia.org/wiki/Fisher_transformation
A couple of helper functions are created as well to calculate the standard deviation and then the 95% confidence interval around a given r with sample size N.
#Conversion to Fischers z'
def r2z(r):
return np.arctanh(r)
def z2r(z):
return np.tanh(z)
def sigmaz(N):
return 1/(N-3)**0.5
def conf_interval(r, N):
z = r2z(r)
sz = sigmaz(N)
lower = z - (2.08 * sz)
upper = z + (2.08 * sz)
return (z2r(z), z2r(lower), z2r(upper))
So what happens when we have low numbers of test samples to calculate the correleation coefficient? The confidence interval gets larger. This is a typical situation as there is usually a wish to put as much data as possible in the training set. So lets assume that we don’t have the 25000 samples in the test set but only maybe 50.
#Choose some random test set out of the 25000 samples
N=50
idx = np.random.choice(range(len(y_tst)), size=N, replace=False)
y_sel = y_tst[idx]
y_pred_ridge = y_pred[idx]
y_pred_rf = rf_y_pred[idx]
#Calculate the correlation coefficients
cor1 = np.corrcoef(y_sel,y_pred_ridge)[0,1]
cor2 = np.corrcoef(y_sel,y_pred_rf)[0,1]
print("Model 1: %0.3F (%0.3F, %0.3F)"%conf_interval(cor1, 50))
print("Model 2: %0.3F (%0.3F, %0.3F)"%conf_interval(cor2, 50))
Model 1: 0.954 (0.917, 0.975)
Model 2: 0.936 (0.886, 0.965)
So Model 1 seems best, but there is a significant overlap of the confidence intervals, so the conclusion is not so straightforward. To get a better confidence that our statistical estimates and transformations is correct, the estimation of R² can be done with many different random selections and the results plotted as histograms.
N=50
coors = []
for i in range(1000):
idx = np.random.choice(range(len(y_tst)), size=N, replace=False)
y_sel = y_tst[idx]
y_pred_ridge = y_pred[idx]
y_pred_rf = rf_y_pred[idx]
cor1 = np.corrcoef(y_sel,y_pred_ridge)[0,1]
cor2 = np.corrcoef(y_sel,y_pred_rf)[0,1]
coors.append([cor1,cor2])
coors = np.array(coors)
_ = plt.hist(coors[:,0], bins=25, alpha=0.5, label= "Model 1")
_ = plt.hist(coors[:,1], bins=25, alpha=0.5, label= "Model 2")
_ = plt.legend()
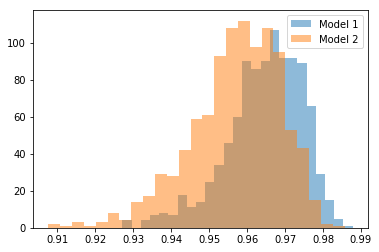
That’s a really huge overlap, and the confidence limits from the previous calculations seem to fit the distributions just nicely and they are a bit skewed as they are not Fischer transformed. Maybe Students t-test or Welch t-test can be used to calculate the probability the two distributions are equal (and reject the null hypothesis that they are), but instead lets use the already sampled distributions to figure out how large a fraction of the times we would be wrong if we just used the naive comparison of the correlation coeffients as they are.
#Counter for how many times correlation 1 > than correlation 2
m1_largest = 0
samples = 10000
for i in range(samples):
m1_cor = np.random.choice(coors[:,0])
m2_cor = np.random.choice(coors[:,1])
m1_larger = m1_cor > m2_cor
m1_largest = m1_largest + m1_larger
print(m1_largest/float(samples))
0.6896
So that’s over 30% of the times, that we would think that one model is the best, compared to the other, rather than the other way round. A huge chance of drawing the wrong conclusion. With a test sample size of 50 it seems to be difficult to compare models directly.
But ….
I think that the comparison need not always to be that bad. The problem is that we assumed that the two correlation should be sampled from different 50 member samples of the test set. I often use a fixed test set rather than making a new for each model each time. So is my naive approach by using a fixed test set any better?
plt.scatter(coors[:,0], coors[:,1], alpha=0.2) plt.plot([0.9,0.99],[0.9,0.99], '-y', lw=5) #Straight line x=y
[]

As this plot shows, there is a clear tendency that randomly selected test sets that give higher correlation in model 1 also give higher correlations for model 2. The two distributions are thus not independent and most of our usual statistical sample theory can’t be applied. But how often are we right about what correlation coefficients is the largest?
m1_largest = np.sum(coors[:,0] > coors[:,1]).astype(float)/coors.shape[0] m1_largest
0.943
This is very much larger than the 68% percent we had before and nearly 95% as is usually the significance limit, with a bit more than 50 samples we could probably get by with a correct conclusion. It do appear that the comparison of correlation coefficients using the same test set is not as difficult as comparing when the test-set is not kept fixed. I’m not sure about if this can be treated statistically, as it may depend on the compared models and how they model the data itself. This paper seem interesting as it suggest more robust way to calculate correlation coefficients: https://www.sciencedirect.com/science/article/pii/S0098300411002251
Take home messages
- Correlation coefficient estimations have an associated uncertainty that is larger for smaller data sets
- Use the sample set size to estimate the uncertainty interval when comparing models with different test/validation sets
- If you keep the test set fixed the direct comparison is easier as the estimation for the two models performance is not independent
- It will probably be a good idea to sample the test set multiple times to get an estimate of the uncertainty and compare the models on different samples.
Hello, nice post.
I have tried replacing the square of the pearson coefficient by the R2 score (coefficient of determination) and strangely the perfect model always lead to significantly lower R2 score than the predictors… Do you understand why this is the case?
Thanks for commenting. No I don’t understand it, it sounds strange. Have you considered that the data are created only with noise in Y? Let us know if you figure out the reason.