I’d like to share a post about a project I’ve been involved in developing—Scikit-Mol. I believe it’s a noteworthy project deserving attention. It has already been featured
Non-conditional De Novo molecular Generation with Transformer Encoders
We’ve known since 2016 that LSTM networks can be used to generate novel and valid SMILES strings of novel molecules after being trained on a dataset of
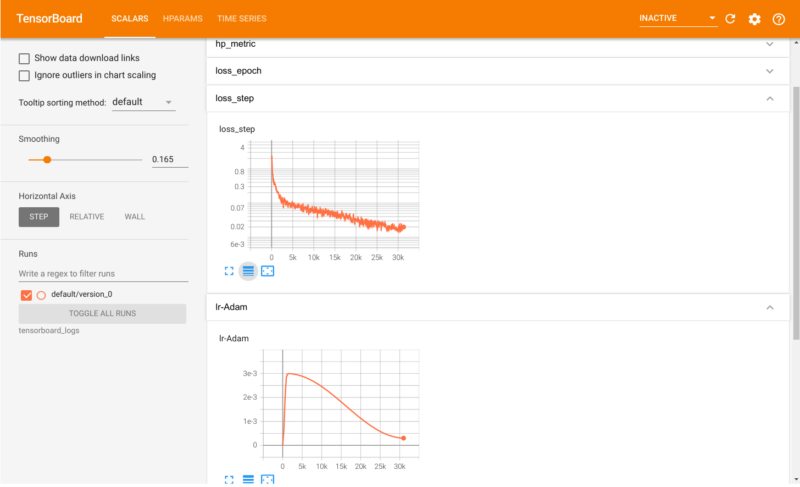
Transformer for Reaction Informatics – utilizing PyTorch Lightning
In the last blogpost I covered how LSTM-to-LSTM networks could be used to “translate” reactants into products of chemical reactions. Performance was however not very good of
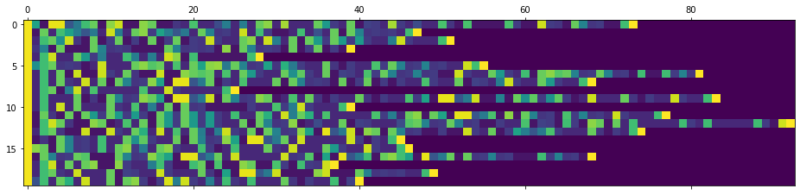
Deep Learning Reaction Prediction with PyTorch
In this blogpost I’ll show how to predict chemical reactions with a sequence to sequence network based on LSTM cells. It’s the same principle as IBM’s RXN

Using GraphINVENT to generate novel DRD2 actives
I have been writing a lot about how to use SMILES together with deep learning architectures such as RNNs and LSTM networks to perform various cheminformatic and
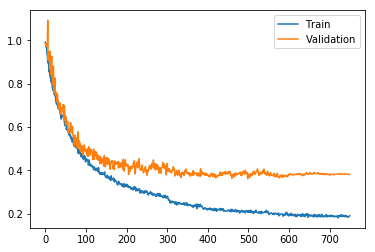
Building a simple SMILES based QSAR model with LSTM cells in PyTorch
Last blog-post I showed how to use PyTorch to build a feed forward neural network model for molecular property prediction (QSAR: Quantitative structure-activity relationship). RDKit was used
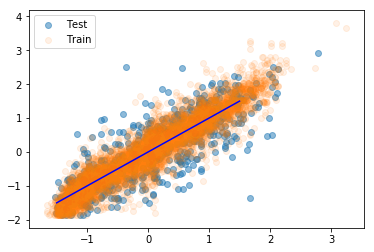
Building a simple QSAR model using a feed forward neural network in PyTorch
In my previous blogposts I’ve entirely been using Keras for my neural networks. Keras as a stand-alone is now no longer active developed, but are instead now
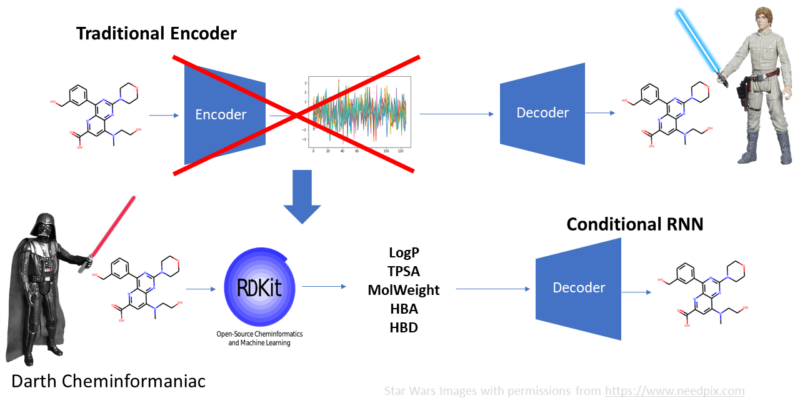
Master your molecule generator 2. Direct steering of conditional recurrent neural networks (cRNNs)
Long time ago in a GPU far-far away, the deep learning rebels are happy. They have created new ways of working with chemistry using deep learning technology
Learn how to make a jupyter notebook widget for annotation of atom properties
Not so long ago Greg Landrum published a blog post with an example of how the SVG rendering from RDKit in a jupyter notebook can be
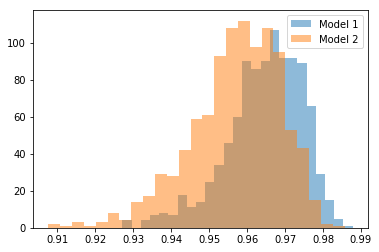
Never do these mistakes when comparing regression models
Some time ago I stumbled upon some work by Patrick Walters which shows that correlation coefficients have a rather large standard error when the sample sets sizes